
4.5 随机增量算法
(Randomized Incremental Algorithm)
我们已经描述了一个 \(O(n \log n)\) 的最优算法和一个 \(O(n^2)\) 的实用算法。人们自然会问,是否存在一个实用的 \(O(n \log n)\) 的算法? 这不仅仅是一个学术问题。 有些应用需要重复计算许多点的凸包,例如,在由复杂多面体模型组成的环境中进行碰撞检测。幸运的是,Clarkson & Shor(1989) 提出了一种随机算法, 能够达到 \(O(n \log n)\) 的期望时间。回顾第 2.4.1 节,这意味着该算法在任何输入上都能以高概率达到这种时间复杂度。
我们在这里简要概述该算法,它是增量算法的一个变体。初看之下,它似乎比原算法更差。回想一下算法 4.1, 我们通过计算点 \(p_i\) 和每个面 \(f\) 确定的四面体的体积来寻找,下一个要添加的点 \(p_i\) 所能见到的面 \(H_{i-1}\)。这种复杂度为 \(O(n)\) 的检查被执行了 \(O(n)\) 次,最终的复杂度为 \(O(n^2)\)。 为了确定哪些面可见,Clarkson-Shor 算法避免了对所有面进行蛮力搜索。它通过一个数据结构,冲突图(conflict graph),来维护两组互补信息来实现。
- 一组针对 \(H_{i-1}\) 中的每个面 \(f\),记录尚未添加的点 \(p_i, p_{i+1}, \dots, p_n\) 中哪些可以看到它。
- 另一组针对每个这样的点 \(p_k\),记录它可以看到的面的集合。
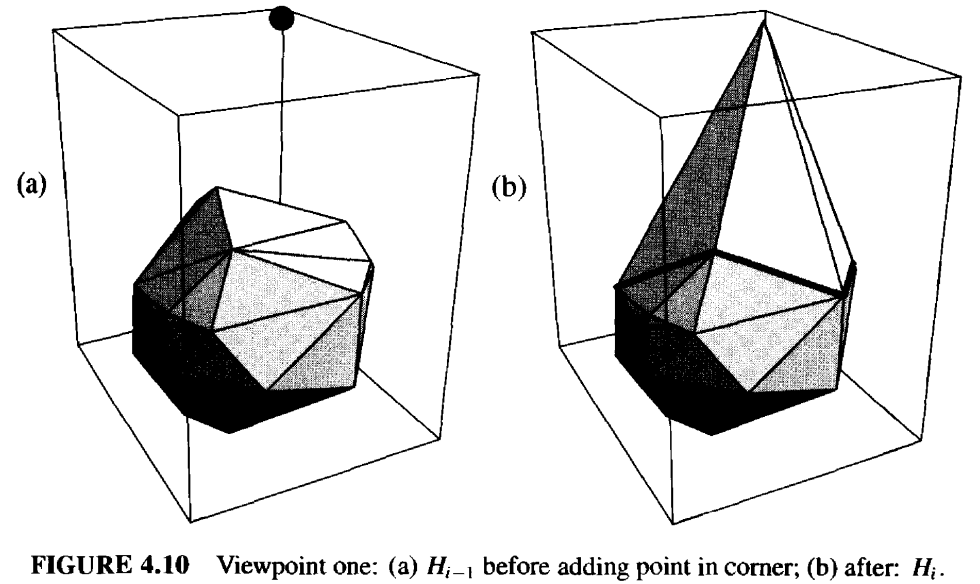
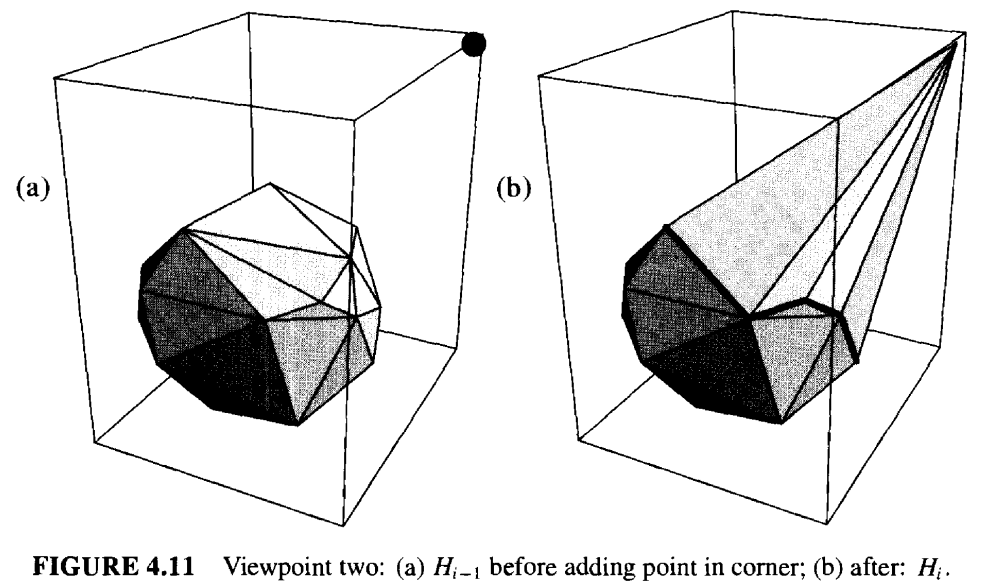
每次迭代都需要更新冲突图。移除关于已删除面的信息很容易。唯一困难的部分是,添加与 \(p_i\) 相关联的新锥面的信息。设 \(f = \text{conv}\{e, p_i\}\) 是一个基于多胞体边缘 \(e\) 的面。 该边缘位于从 \(p_i\) 可见和不可见的面之间的边界上。如果 \(p_k\) 能看到 \(f\),那么它至少能够看到 \(H_{i-1}\) 中与 \(e\) 相邻的两个面中的一个,如图4.10 和图 4.11所示。
 |
 |
虽然这给出了如何在每次迭代中更新冲突图的提示,但整体复杂度是否得到改善一点也不清楚。这需要微妙的分析才能得到 \(O(n \log n)\) 的期望复杂度。 参见 Mulmuley (1994, Sec. 3.2) 或 de Berg, et al. (1997, Sec. 11.2)。幸运的是,这种微妙的分析并没有使算法本身变得更加复杂。
4.5.1. 练习 (Exercises)
- 冲突更新Conflict updates。证明上述命题,即如果 \(p_k\) 能看见 \(f = \text{conv} \{e, p_i\}\), 那么它必然能看见与 \(e\) 相邻的两个面中的至少一个,或两个。利用这一点详细说明一种高效的更新过程。
- [Programming] 实现Implementation。修改 chull.c 以维护一个冲突图。对其进行测试,并观察 \(n \approx 10^5\) 时,搜索量的减少是否能弥补图更新的开销。